
Part of the Physical AI Series
This article builds on earlier discussions in the Physical AI series, which explores how intelligent systems interact with the physical world and how they are structured in real-world deployments.
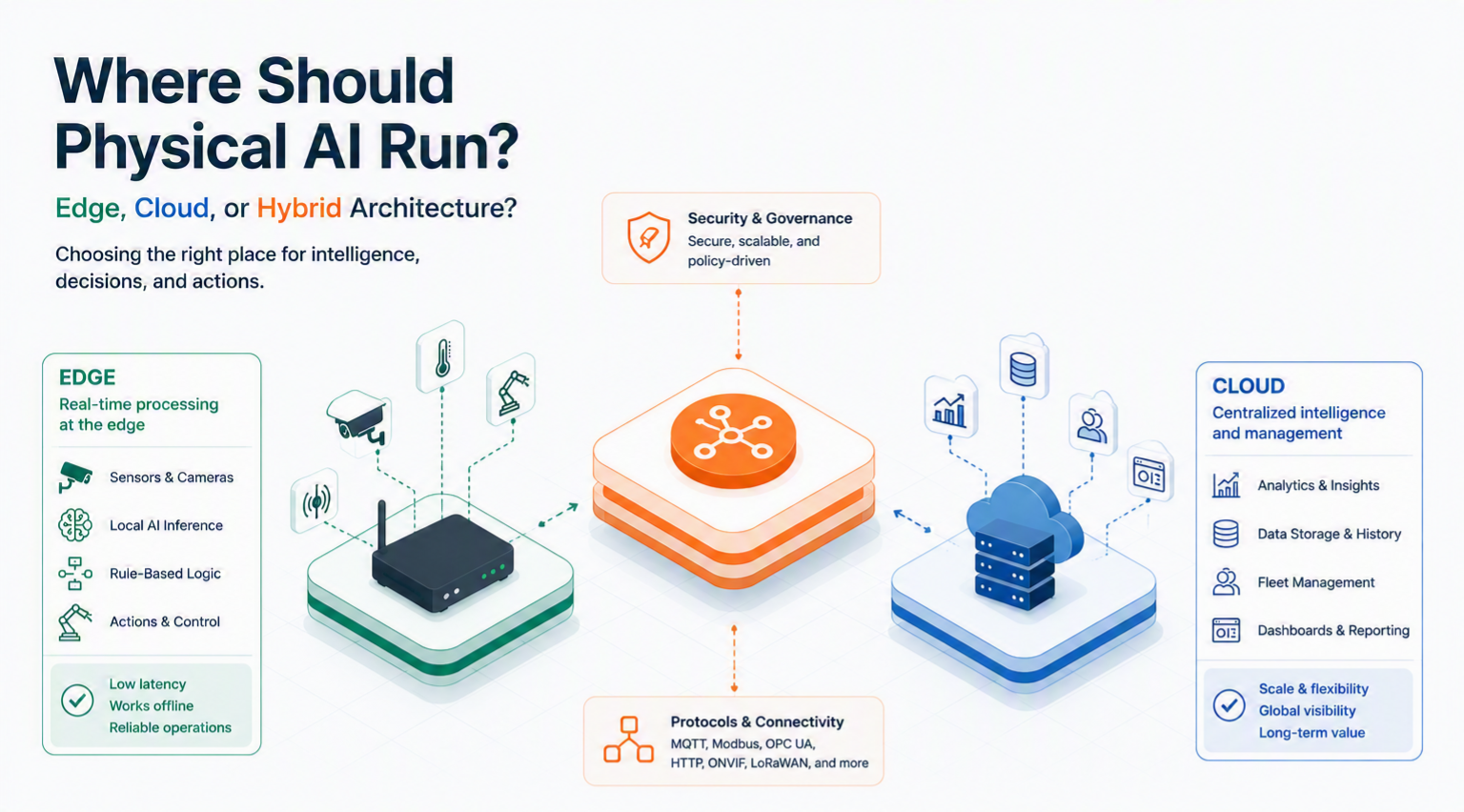
As organizations explore Physical AI, much of the discussion naturally focuses on models, sensors, and automation. However, one of the most important architectural decisions is often overlooked: where should the intelligence actually run?
In traditional AI deployments, cloud infrastructure has been the default choice. Data is collected, transmitted to centralized platforms, processed, and then returned as insights or actions.
For many Physical AI applications, this approach quickly encounters limitations.
Unlike digital systems that can tolerate delays, Physical AI operates within real-world environments where events unfold continuously. A manufacturing safety alert, a building access event, or a security incident cannot pause while waiting for a response from a distant cloud service. Furthermore, cloud services often pose a single point of failure. If the connectivity is lost, the entire system is down. However if the system is distributed at the edge in a decentralized way, it becomes much more resilient.
This is why Physical AI increasingly relies on edge-first, distributed architectures.
A chatbot can tolerate a delay of several seconds without significantly impacting the user experience. A recommendation engine can process information asynchronously and still deliver value.
Physical systems operate differently.
When a machine enters an unsafe condition, an unauthorized individual enters a restricted area, or an environmental threshold is exceeded, decisions often need to happen immediately.
As Physical AI moves closer to operational processes, responsiveness becomes increasingly important. The closer the system is to the event, the faster it can react.
This is one of the primary reasons edge computing has become a foundational component of Physical AI architectures.
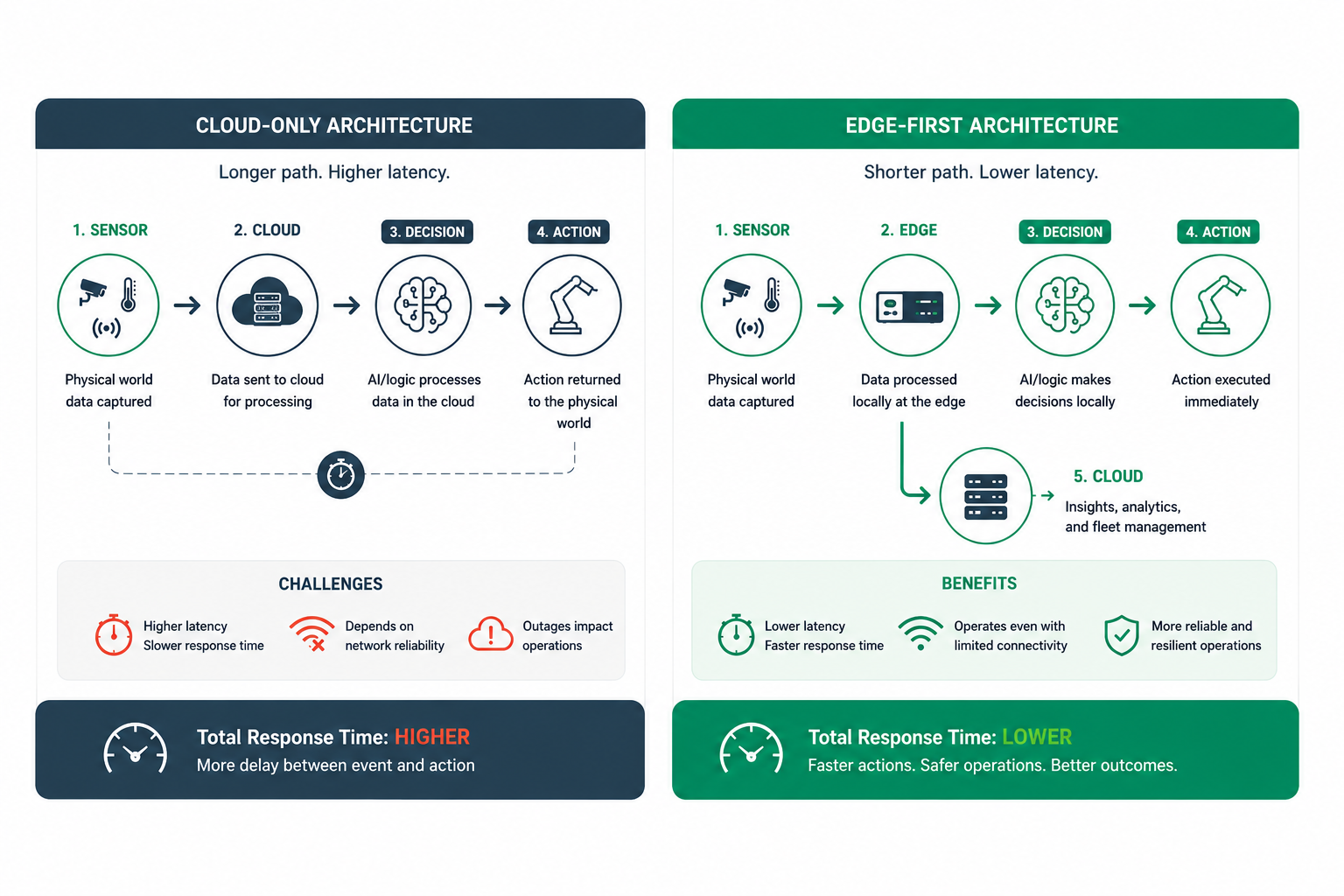
The Latency Challenge every interaction with a cloud service introduces delay.
Data must be transmitted across networks, processed remotely, and returned before any action can be taken. For many business applications, this delay is acceptable. For Physical AI systems, it can become a significant constraint.
Consider examples such as:
In these scenarios, delays can reduce effectiveness, increase operational risk, or create a poor user experience.
Processing data closer to where it is generated allows organizations to reduce latency and improve responsiveness without relying on constant communication with centralized systems.
This creates an important challenge for cloud-dependent architectures that rely on connectivity, which can pose the risk of a single point of failure.
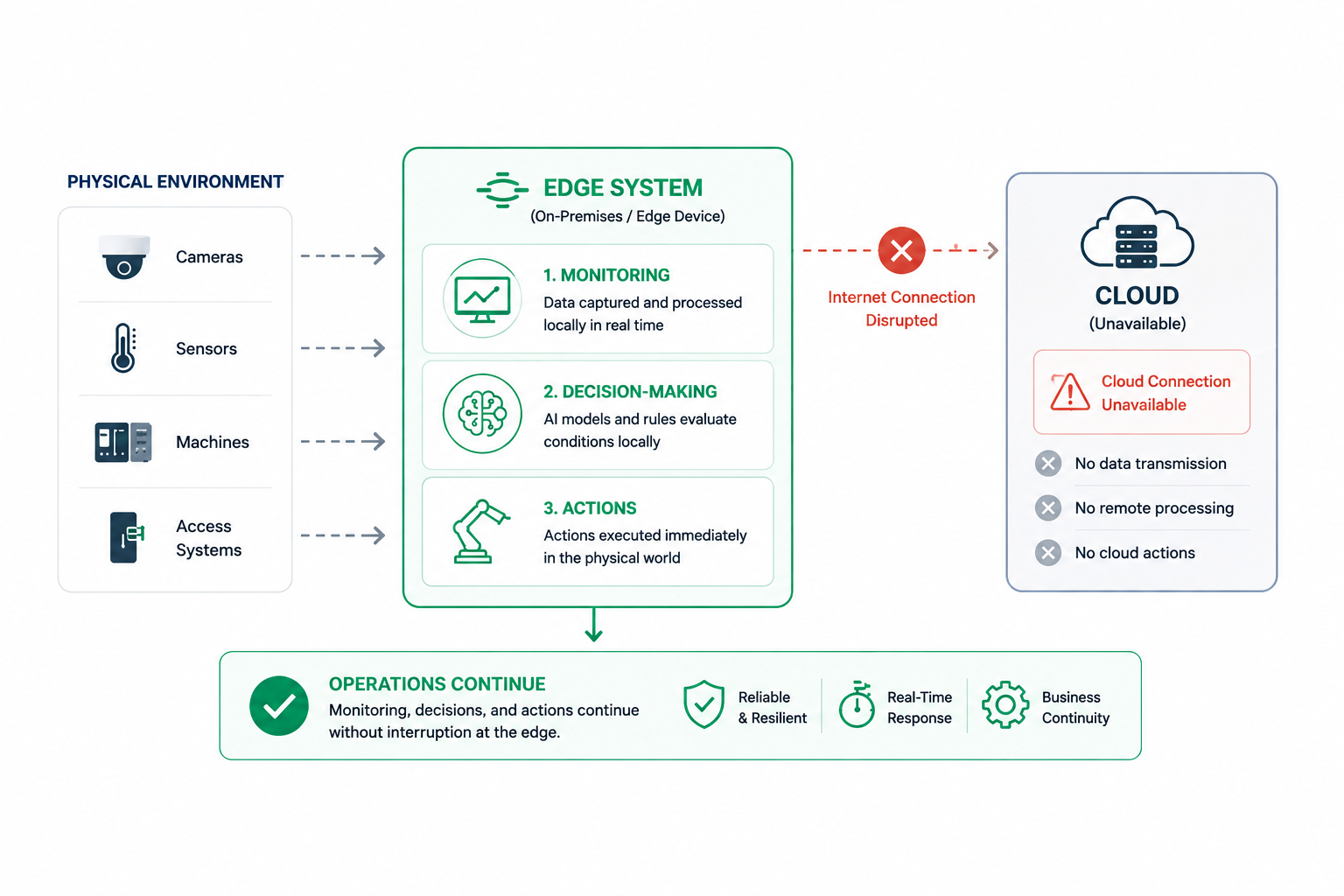
What happens when:
The physical environment does not stop.
Machines continue running. People continue moving through facilities. Infrastructure continues operating.
For this reason, many Physical AI deployments must be capable of:
even when disconnected from the cloud.
This level of resilience is one of the strongest arguments for a distributed, edge-first design.
Organizations operating in healthcare, manufacturing, critical infrastructure, and government environments often cannot send all operational data to external systems.
In some cases, regulations require data to remain on-premises. In others, organizations simply prefer to maintain greater control over sensitive operational information.
Edge architectures help address these requirements by allowing data processing and decision-making to occur locally while still enabling selective integration with cloud services where appropriate.
Cloud platforms continue to provide significant value through:
Rather than choosing between edge and cloud, most successful deployments combine both.
A common architecture looks like this:
Edge
Cloud
This hybrid approach allows organizations to balance responsiveness, scalability, and governance.
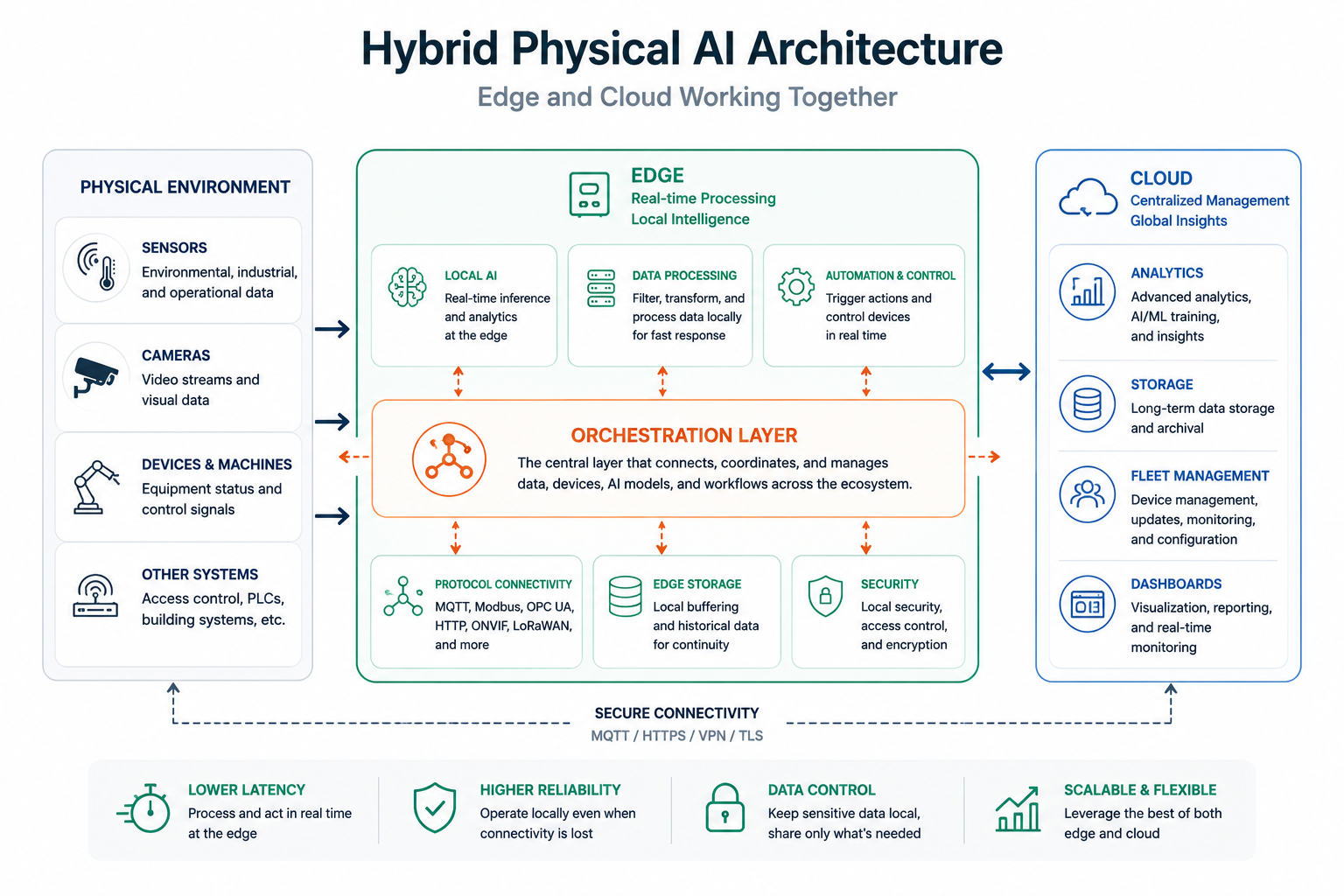
As discussed in the previous article, orchestration is often the layer that determines whether a Physical AI deployment can scale beyond a proof of concept.
In edge-first environments, orchestration becomes even more important.
Gravio is designed to operate across the edge and orchestration layers of the Physical AI stack, enabling organizations to process data locally, coordinate workflows, and connect sensors, devices, AI models, and enterprise systems.
Its distributed node architecture allows deployments to operate at the edge, in the cloud, or across hybrid environments, while continuing to bridge IT and OT systems within a unified framework.
This enables organizations to deploy Physical AI closer to where events occur while maintaining flexibility as requirements evolve.
As a result, architecture becomes just as important as intelligence.
Latency, reliability, operational continuity, and data sovereignty are not secondary considerations. They are often the factors that determine whether a deployment succeeds in the real world.
For this reason, edge-first architectures are increasingly becoming a practical requirement rather than a technical preference. As Physical AI continues to mature, organizations that can combine local intelligence with centralized visibility will be best positioned to build systems that are responsive, resilient, and scalable.
In the next article, we will explore a question that many organizations encounter after their first deployment: if the technology is available and the architecture is understood, why do so many Physical AI initiatives still struggle to move beyond the proof-of-concept stage?
